
In the last post we showed that under mild assumptions ($n = \Omega(K)$ and Gaussian noise), the regret in the worst case is at least $\Omega(\sqrt{Kn})$. More precisely, we showed that for every policy $\pi$ and $n\ge K-1$ there exists a $K$-armed stochastic bandit problem $\nu\in \mathcal E_K$ with unit variance Gaussian rewards and means in $[0,1]$ such that the regret $R_n(\pi,\nu)$ of $\pi$ on $\nu$ satisfies $R_n(\pi,\nu) \geq c\sqrt{nK}$ for some universal constant $c > 0$, or
\begin{align*}
R_n^*(\cE_K)\doteq\inf_\pi \sup_{\nu \in \cE_K} R_n(\pi,\nu)\ge c \sqrt{nK}\,.
\end{align*}
Earlier we have also seen that the regret of UCB on such problems is at most $C \sqrt{nK \log(n)}$ with some universal constant $C>0$: $R_n(\mathrm{UCB},\cE_K)\le C \sqrt{nK\log(n)}$. Thus, UCB is near minimax-optimal, in the sense that except for a logarithmic factor its upper bound matches the lower bound for $\cE_K$.
Does this mean that UCB is necessarily a good algorithm for class $\cE_K$? Not quite! Consider the following modification of UCB, which we will call by the descriptive, but not particularly flattering name UCBWaste. Choose $0 < C' \ll C$, where $C$ is the universal constant in the upper bound on the regret of UCB (if we actually calculated the value of $C$, we could see that e.g. $C'=0.001$ would do). Then, in the first $m=C'\sqrt{Kn}$ rounds, UCBWaste will explore each of the $K$ actions equally often, after which it switches to the UCB strategy. It is easy to see that from the perspective of worst-case regret, UCBWaste is almost as good as UCB (being at most $C'\sqrt{Kn}$ worse). Would you accept UCBWaste as a good policy?
Perhaps not. To see why, consider for example a problem $\nu\in \cE_K$ such that on $\nu$ the immediate regret for choosing any suboptimal action is close to one. From the regret analysis of UCB we can show that after seeing a few rewards from some suboptimal action, with high probability UCB will stop using that action. As a result, UCB on $\nu$ would achieve a very small regret. In fact, it follows from our previous analysis that for sufficiently large $n$, UCB will achieve a regret of $\sum_{i:\Delta_i(\nu)>0} \frac{C\log(n)}{\Delta_i(\nu)} \approx C K \log(n)$, where $\Delta_i(\nu)$ is the suboptimality gap of action $i$ in $\nu$. However, UCBWaste, true to its name, will suffer a regret of at least $C’\sqrt{Kn/2}$ on $\nu$, a quantity that for $n$ large is much larger than the logarithmic bound on the regret of UCB.
Thus, on the “easy”, or “nice” instances, UCBWaste’s regret seems to be unnecessarily large at least as $n\to\infty$, even though UCBWaste is a near worst-case optimal algorithm for any $n$. If we care about what happens for $n$ large (and why should not we — after all, having higher standards should not hurt), it may be worthwhile to look beyond finite-time worst-case optimality.
Algorithms that are nearly worst-case optimal may fail to take advantage of environments that are not the worst case. What is more desirable is to have algorithms which are near worst-case optimal, while their performance gets better on “nicer” instances.
But what makes an instance “nice”? For a fixed $K$-action stochastic bandit environment $\nu$ with $1$-subgaussian reward-noise, the regret of UCB was seen to be logarithmic and in particular
\begin{align}
\limsup_{n\to\infty} \frac{R_n}{\log(n)} \leq c^*(\nu) \doteq \sum_{i:\Delta_i(\nu) > 0} \frac{2}{\Delta_i(\nu)}\,.
\label{eq:cnudef}
\end{align}
Then perhaps $c^*(\nu)$ could be used as an intrinsic measure of the difficulty of learning on $\nu$. Or perhaps there exist some constant $c'(\nu)$ that is even smaller than $c^*(\nu)$ such that some strategy suffers at most $c'(\nu) \log(n)$ regret asymptotically? If, for example, $c'(\nu)$ is smaller by a factor of two than $c^*(\nu)$, then this could be a big difference!
In this post we will show that, in some sense, $c^*(\nu)$ is the best possible. In particular, we will show that no reasonable strategy can outperform UCB in the asymptotic sense above on any problem instance $\nu$. This is a big difference from the previous approach because the “order of quantifiers” is different: In the minimax result proven in the last post we showed that for any policy $\pi$ there exists a bandit instance $\nu \in \cE_K$ on which $\pi$ suffers large regret. Here we show that for all reasonable policies $\pi$, the policy’s asymptotic regret is always at least as large as that of UCB.
We have not yet said what we mean by reasonable. Clearly for any $\nu$, there are policies for which $\limsup_{n\to\infty} R_n / \log(n) = 0$. For example, the policy that chooses $A_t = \argmax_i \mu_i(\nu)$. But this is not a reasonable policy because it suffers linear regret for any $\nu’$ such that the optimal action of $\nu$ is not optimal in $\nu’$. At least, we should require that the policy achieves sublinear regret over all problems. This may still look a bit wasteful because UCB achieves logarithmic asymptotic regret for any $1$-subgaussian problem. A compromise between the undemanding sublinear and the perhaps overly restrictive logarithmic growth is to require that the policy has subpolynomial regret growth, a choice that has historically been the most used, and which we will also take. The resulting policies are said to be consistent.
Asymptotic lower bound
To firm up the ideas, define $\cE_K’$ as the class of $K$-action stochastic bandits where each action has a reward distribution with $1$-subgaussian noise. Further, let $\cE_K'(\mathcal N)\subset \cE_K’$ be those environments in $\cE_K’$ where the reward distribution is Gaussian. Note that for minimax lower bounds it is important to assume the sub-optimality gaps are bounded from above, this is not required in the asymptotic setting. The reason is that any reasonable (that word again) strategy should choose each arm at least once, which does not affect the asymptotic regret at all, but does affect the finite-time minimax regret.
Definition (consistency): A policy $\pi$ is consistent over $\cE$ if for all bandits $\nu \in \mathcal \cE$ and for all $p>0$ it holds that
\begin{align}\label{eq:subpoly}
R_n(\pi,\nu) = O(n^p)\, \quad \text{ as } n \to\infty\,.
\end{align}
We denote the class of consistent policies over $\cE$ by $\Pi_{\text{cons}}(\cE)$.
Note that $\eqref{eq:subpoly}$ trivially holds for $p\ge 1$. Note also that because $n \mapsto n^p$ is positive-valued, the above is equivalent to saying that for each $\nu \in \cE$ there exists a constant $C_\nu>0$ such that $R_n(\pi,\nu) \le C_\nu n^p$ for all $n\in \N$. In fact, one can also show that above we can also replace $O(\cdot)$ with $o(\cdot)$ with no effect on whether a policy is called consistent or not. Just like in statistics, consistency is a purely asymptotic notion.
We can see that UCB is consistent (its regret is logarithmic) over $\cE_K’$. On the other hand, the strategy that always chooses a fixed action $i\in K$ is not consistent (if $K > 1$) over any reasonable $\cE$, since its regret is linear in any $\nu$ where $i$ is suboptimal.
The main theorem of this post is that no consistent strategy can outperform UCB asymptotically in the Gaussian case:
Theorem (Asymptotic lower bound for Gaussian environments): For any policy $\pi$ consistent over the $K$-action unit-variance Gaussian environments $\cE_K'(\mathcal N)$ and any $\nu\in \cE_K'(\mathcal N)$, it holds that
\begin{align*}
\liminf_{n\to\infty} \frac{R_n(\pi,\nu)}{\log(n)} \geq c^*(\nu)\,,
\end{align*}
where recall that $c^*(\nu)= \sum_{i:\Delta_i(\nu)>0} \frac{2}{\Delta_i(\nu)}$.
Since UCB is consistent for $\cE_K’\supset \cE_K'(\mathcal N)$,
\begin{align*}
c^*(\nu) = \inf_{\pi \in \Pi_{\text{cons}}(\cE_K'(\mathcal N))} \liminf_{n\to\infty} \frac{R_n(\pi,\nu)}{\log(n)}
\le
\limsup_{n\to\infty} \frac{R_n(\text{UCB},\nu)}{\log(n)}\le c^*(n)\,,
\end{align*}
that is
\begin{align*}
\inf_{\pi \in \Pi_{\text{cons}}(\cE_K'(\mathcal N))} \liminf_{n\to\infty} \frac{R_n(\pi,\nu)}{\log(n)}
=
\limsup_{n\to\infty} \frac{R_n(\text{UCB},\nu)}{\log(n)} = c^*(\nu)\,.
\end{align*}
Thus, we see that UCB is asymptotically optimal over the class of unit variance Gaussian environments $\cE_K'(\mathcal N)$.
Proof
Pick a $\cE_K'(\mathcal N)$-consistent policy $\pi$ and a unit variance Gaussian environment $\nu =(P_1,\dots,P_K)\in \cE_K'(\mathcal N)$ with mean rewards $\mu \in \R^K$. We need to lower bound $R_n \doteq R_n(\pi,\nu)$. Let $\Delta_i \doteq \Delta_i(\nu)$. Based on the basic regret decomposition identity $R_n = \sum_i \Delta_i \E_{\nu,\pi}[T_i(n)]$, it is not hard to see that the result will follow if for any action $i\in [K]$ that is suboptimal in $\nu$ we prove that
\begin{align}
\liminf_{n\to\infty} \frac{\E_{\nu,\pi}[T_i(n)]}{\log(n)} \ge \frac{2}{\Delta_i^2}\,.
\label{eq:armlowerbound}
\end{align}
As in the previous lower bound proof, we assume that all random variables are defined over the canonical bandit measurable space $(\cH_n,\cF_n)$, where $\cH_n = ([K]\times \R)^n$, $\cF_n$ is the restriction of $\mathcal L(R^{2n})$ to $\cH_n$, and $\PP_{\nu,\pi}$ (which induces $\E_{\nu,\pi}$) is the distribution of $n$-round action-reward histories induced by the interconnection of $\nu$ and $\pi$.
The intuitive logic of the lower bound is as follows: $\E_{\nu,\pi}[T_i(n)]$ must be (relatively) large because the regret in all environments $\nu’$ where (as opposed to what happens in $\nu$) action $i$ is optimal must be small by our assumption that $\pi$ is a “reasonable” policy and for this $\E_{\nu’,\pi}[T_i(n)]$ must be large. However, if the gap $\Delta_i$ is small and $\nu’$ is close to $\nu$, $\E_{\nu,\pi}[T_i(n)]$ will necessarily be large when $\E_{\nu’,\pi}[T_i(n)]$ is large because the distributions $\PP_{\nu,\pi}$ and $\PP_{\nu’,\pi}$ will also be close.
As in the previous lower bound proof, the divergence decomposition identity and the high-probability Pinsker inequality will help us to carry out this argument. In particular, from the divergence decomposition lemma, we get that for any $\nu’=(P’_1,\dots,P_K’)$ such that $P_j=P_j’$ except for $j=i$,
\begin{align}
\KL(\PP_{\nu,\pi}, \PP_{\nu’,\pi}) = \E_{\nu,\pi}[T_i(n)] \, \KL(P_i, P’_i)\,,
\label{eq:infoplem}
\end{align}
while the high-probability Pinsker inequality gives that for any event $A$,
\begin{align*}
\PP_{\nu,\pi}(A)+\PP_{\nu’,\pi}(A^c)\ge \frac12 \exp(-\KL(\PP_{\nu,\pi}, \PP_{\nu’,\pi}) )\,,
\end{align*}
or equivalently,
\begin{align}
\KL(\PP_{\nu,\pi},\PP_{\nu’,\pi}) \ge \log \frac{1}{2 (\PP_{\nu,\pi}(A)+\PP_{\nu’,\pi}(A^c))}\,.
\label{eq:pinsker}
\end{align}
We now upper bound $\PP_{\nu,\pi}(A)+\PP_{\nu’,\pi}(A^c)$ in terms of $R_n+R_n’$ where $R_n’ = R_n(\nu’,\pi)$. For this choose $P_i’ = \mathcal N(\mu_i+\lambda,1)$ with $\lambda>\Delta_i$ to be selected later. Further, we choose $A= \{ T_i(n)\ge n/2 \}$ and thus $A^c = \{ T_i(n) < n/2 \}$. These choices make $\PP_{\nu,\pi}(A)+\PP_{\nu',\pi}(A^c)$ small if $R_n$ and $R_n'$ are both small. Indeed, since $i$ is suboptimal in $\nu$ and $i$ is optimal in $\nu'$ and for any $j\ne i$, $\Delta_j'(\nu) \ge \lambda-\Delta_i$,
\begin{align*}
R_n \ge \frac{n\Delta_i}{2} \PP_{\nu,\pi}(T_i(n)\ge n/2 ) \, \text{ and }
R_n' \ge \frac{n (\lambda-\Delta_i) }{2} \PP_{\nu',\pi}( T_i(n) < n/2 )\,.
\end{align*}
Summing these up, lower bounding $\Delta_i/2$ and $(\lambda-\Delta_i)/2$ by $\kappa(\Delta_i,\lambda) \doteq \frac{\min( \Delta_i, \lambda-\Delta_i )}{2}$, and then reordering gives
\begin{align*}
\PP_{\nu,\pi}( T_i(n) \ge n/2 ) + \PP_{\nu’,\pi}( T_i(n) < n/2 )
\le \frac{R_n+R_n'}{ \kappa(\Delta_i,\lambda) \,n}
\end{align*}
as promised.
Combining this inequality with $\eqref{eq:infoplem}$ and $\eqref{eq:pinsker}$ and using $\KL(P_i,P'_i) = \lambda^2/2$ we get
\begin{align}
\frac{\lambda^2}{2}\E_{\nu,\pi}[T_i(n)] \ge
\log\left( \frac{\kappa(\Delta_i,\lambda)}{2} \frac{n}{R_n+R_n'} \right)
=
\log\left( \frac{\kappa(\Delta_i,\lambda)}{2}\right)
+ \log(n) - \log(R_n+R_n')\,.
\end{align}
Dividing both sides by $\log(n)$, we see that it remains to upper bound $\frac{\log(R_n+R_n')}{\log(n)}$. For this, note that for any $p>0$ $R_n+ R_n’ \le C n^p$ for all $n$ and some constant $C>0$. Hence, $\log(R_n+R_n’) \le \log(C) + p\log(n)$, from which we get that $\limsup_{n\to\infty} \frac{\log(R_n+R_n’)}{\log(n)} \le p$. Since $p>0$ was arbitrary, it follows that this also holds for $p=0$. Hence,
\begin{align}
\liminf_{n\to\infty}
\frac{\lambda^2}{2} \frac{\E_{\nu,\pi}[T_i(n)]}{\log(n)} \ge
1 – \limsup_{n\to\infty} \frac{\log(R_n+R_n’)}{\log(n)} \ge 1\,.
\end{align}
Taking the infimum of both sides over $\lambda>\Delta_i$ and reordering gives $\eqref{eq:armlowerbound}$, thus finishing the proof.
QED
Instance-dependent finite-time lower bounds
Is it possible to go beyond asymptotic instance optimality? Yes, of course! All we have to do is to redefine what is meant by a “reasonable” algorithm. One idea is to call an algorithm reasonable when its finite-time(!) regret is close to minimax optimal. The situation is illustrated in the graph below:
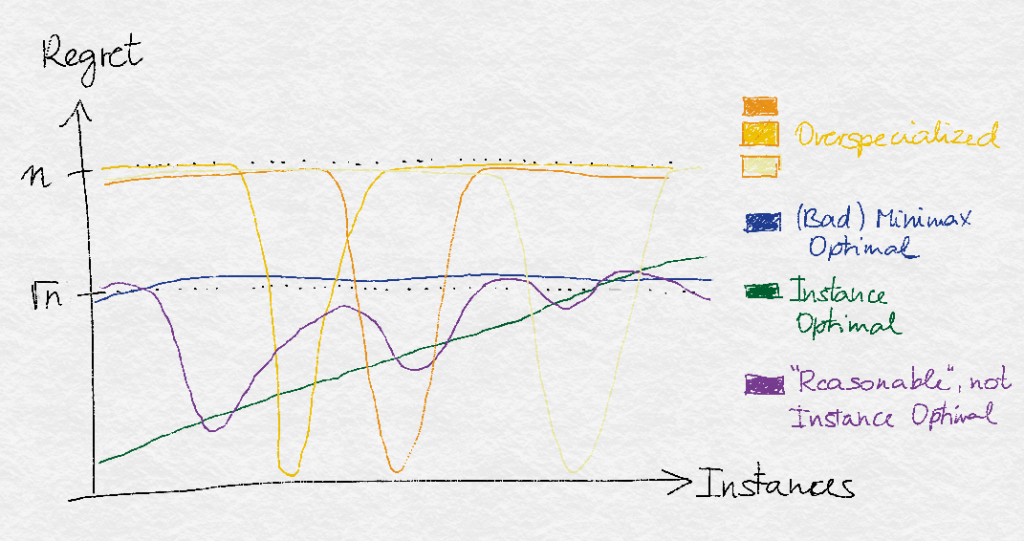
Illustration of optimality concepts. The $x$ axis lists instances, ordered so that the “green” graph looks nice. Shown are the regret of various policies in different colors. While a near minimax algorithm can perform equally over all instances (and never much worse than the largest of the curves’ minimum values), a near instance optimal algorithm is required to come close to what is best on every instance using reasonable algorithms. The reasonable class can be the algorithms which are near minimax optimal.
In this part we will show instance-optimal finite-time lower bounds building on the ideas of the previous proof. This proof by and large uses the same ideas as the proof of the minimax result in the last post. This suggests that for future reference it may be useful to extract the common part, which summarizes what can be obtained by chaining the high-probability Pinsker inequality with the divergence decomposition lemma:
Lemma (Instance-dependent lower bound): Let $\nu = (P_i)_i,\nu’=(P’_i)$ be $K$-action stochastic bandit environments that differ only the distribution of the rewards for action $i\in [K]$. Further, assume that $i$ is suboptimal in $\nu$ and is optimal in $\nu’$, and in particular $i$ is the unique optimal action in $\nu’$. Let $\lambda = \mu_i(\nu’)-\mu_i(\nu)$. Then, for any policy $\pi$,
\begin{align}\label{eq:idalloclb}
D(P_i,P_i’) \E_{\nu,\pi} [T_i(n)] \ge \log\left( \frac{\min\set{\lambda – \Delta_i, \Delta_i}}{4}\right) + \log(n) – \log(R_n+R_n’)\,.
\end{align}
Note that the lemma holds for finite $n$ and any $\nu$ and can be used to derive finite-time instance-dependent lower bounds for any environment class $\cE$ that is rich enough to include a pair $\nu’$ for any $\nu \in \cE$ and for policies that are uniformly good over $\cE$. For illustration consider the Gaussian unit variance environments $\cE\doteq \cE_K(\mathcal N)$ and policies $\pi$ whose regret, on any $\nu\in \cE$, is bounded by $C n^p$ for some $C>0$ and $p>0$. Call this class $\Pi(\cE,C,n,p)$, the class of $p$-order policies. Note that UCB is in this class with $C = C’\sqrt{K \log(n)}$ and $p=1/2$ with some $C’>0$. Thus, for $p\ge 1/2$ and suitable $C$ this class is not empty.
As an immediate corollary of the previous lemma we get the following result:
Theorem (Finite-time, instance-dependent lower bound for $p$-order policies): Take $\cE$ and $\Pi(\cE,C,n,p)$ as in the previous paragraph. Then, for any $\pi \in \Pi(\cE,C,n,p)$ and $\nu \in \cE$, the regret of $\pi$ on $\nu$ satisfies
\begin{align}
R_n(\pi,\nu) \ge
\frac{1}{2} \sum_{i: \Delta_i>0} \left(\frac{(1-p)\log(n) + \log(\frac{\Delta_i}{8C})}{\Delta_i}\right)^+\,,
\label{eq:finiteinstancebound}
\end{align}
where $(x)^+ = \max(x,0)$ is the positive part of $x\in \R$.
Proof: Given $\nu=(\mathcal N(\mu_i,1))_i$, $i$ such that action $i$ is suboptimal in $\nu$, choose $\nu_i’ = (\mathcal N(\mu_j’,1))_j$ such that $\mu_j’=\mu_j$ unless $j=i$, in which make $\mu_i’ = \mu_i+\lambda$, $\lambda\le 2\Delta_i(\nu)$. Then, $\nu’\in \cE$ and from $\log(R_n+R_n’) \le \log(2C)+p\log(n)$ and $\eqref{eq:idalloclb}$, we get
\begin{align*}
\E_{\nu,\pi} [T_i(n)]
\ge \frac{2}{\lambda^2}\left(\log\left(\frac{n}{2Cn^p}\right) + \log\left(\frac{\min\set{\lambda – \Delta_i, \Delta_i}}{4}\right)\right)
\end{align*}
Choosing $\lambda = 2\Delta_i$ and plugging this into the basic regret decomposition identity gives the result.
QED
With $p=1/2$, $C = C’\sqrt{K}$ with $C’>0$ suitable so that $\Pi(\cE,C’\sqrt{K},n,1/2)\ne \emptyset$ we get for any policy $\pi$ that is “near-minimax optimal” for $\cE$ that
\begin{align}
R_n(\pi,\nu) \ge \frac{1}{2} \sum_{i: \Delta_i>0} \left(\frac{\frac12\log(n) + \log(\frac{\Delta_i}{8C’ \sqrt{K}})}{\Delta_i}\right)^+\,.
\label{eq:indnearminimaxlb}
\end{align}
The main difference to the asymptotic lower bound is twofold: First, when $\Delta_i$ is very small, the corresponding term is eliminated in the lower bound: For small $\Delta_i$, the impact of choosing for $n$ small action $i$ is negligible. Second, even when $\Delta_i$ are all relatively large, the leading term in this lower bound is approximately half that of $c^*(\nu)$. This effect may be real: The class of policies considered is larger than in the asymptotic lower bound, hence there is the possibility that the policy that is best tuned for a given environment achieves a smaller regret. At the same time, we only see a constant factor difference.
The lower bound $\eqref{eq:indnearminimaxlb}$ should be compared to the upper bound derived for UCB. In particular, recall that the simplified form of an upper bound was $\sum_{i:\Delta_i>0} \frac{C \log(n)}{\Delta_i}$. We see that the main difference to the above bound is the lack of the second term in $\eqref{eq:indnearminimaxlb}$. With some extra work, this gap can also be closed.
We now argue that the previous lower bound is not too weak in that in some sense it allows us to recover our previous minimax lower bound. In particular, choosing $\Delta_i= 8 \rho C n^{p-1}$ uniformly for all but one optimal action, we get $(1-p)\log(n)+\log(\frac{\Delta_i}{8C}) = \log(\rho)$. Plugging this into $\eqref{eq:finiteinstancebound}$ and lower bounding $\sup_{\rho>0}\log(\rho)/\rho = \exp(-1)$ by $0.35$ gives the following corollary:
Corollary (Finite-time lower bound for $p$-order policies): Take $\cE$ and $\Pi(\cE,C,n,p)$ as in the previous paragraph. Then, for any $\pi \in \Pi(\cE,C,n,p)$,
\begin{align*}
\sup_{\nu\in \cE} R_n(\pi,\nu) \ge \frac{0.35}{16} \frac{K-1}{C} n^{1-p} \,.
\end{align*}
When $C = C’\sqrt{K}$ and $p=1/2$, we get the familiar $\Omega( \sqrt{Kn} )$ lower bound. However, note the difference: Whereas the previous lower bound was true for any policy, this lower bound holds only for policies in $\Pi(\cE,C’\sqrt{K},n,1/2)$. Nevertheless, it is reassuring that the instance-dependent lower bound is able to recover the minimax lower bound for the “near-minimax” policies. And to emphasize the distinction even further. In our minimax lower bound we only showed there exists an environment for which the lower bound holds, while the result above holds no matter which arm we choose to be the optimal one. This is only possible because we restricted the class of algorithms.
Summary
So UCB is close to minimax optimal (last post) and now we have seen that at least among the class of consistent strategies it is also asymptotically optimal and also almost optimal for any instance amongst the near-minimax optimal algorithm even in a non-asymptotic sense. One might ask if there is anything left to do, and like always the answer is: Yes, lots!
For one, we have only stated the results for the Gaussian case. Similar results are easily shown for alternative classes. A good exercise is to repeat the derivations in this post for the class of Bernoulli bandits, where the rewards of all arms are sampled from a Bernoulli distribution.
There is also the question of showing bounds that hold with high probability rather than in expectation. So far we have not discussed any properties of the distribution of the regret other than its mean, which we have upper bounded for UCB and lower bounded here and in the last post. In the next few posts we will develop algorithms for which the regret is bounded with high probability and so the lower bounds of this nature will be delayed for a little while.
Notes, references
There are now a wide range of papers with lower bounds for bandits. For asymptotic results the first article below was the earliest that we know of, while others are generalizations.
- Lai and Robbins. Asymptotically Efficient Adaptive Allocation Rules. 1985
- Lai and Graves. Asymptotically Efficient Adaptive Choice of Control Laws in Controlled Markov Chains. 1997
- Burnetas and Katehakis. Optimal Adaptive Policies for Sequential Allocation Problems. 1996
For non-minimax results that hold in finite time there are very recently a variety of approaches (and one older one). They are:
- Garivier, Stoltz and Ménard. Explore First, Exploit Next: The True Shape of Regret in Bandit Problems. 2016
- Kulkarni and Lugosi. Finite-time lower bounds for the two-armed bandit problem. 2000
- Wu, György and Szepesvári Online Learning with Gaussian Payoffs and Side Observations, NIPS, 2015
- Lattimore. Regret Analysis of the Anytime Optimally Confident UCB. 2016
Finally, for the sake of completeness we note that minimax bounds are available in the following articles. The second of which deals with the high-probability case mentioned above.
- Peter Auer, Nicolo Cesa-Bianchi, Yoav Freund, and Robert E. Schapire. Gambling in a rigged casino: The adversarial multi-armed bandit problem, 1995
- Gerchinovitz and Lattimore. Refined Lower Bounds for Adversarial Bandits. 2016
Note 1. All of the above results treat all arms symmetrically. Sometimes one might want an algorithm that treats the arms differently and for which the regret guarantee depends on which arm is optimal. We hope eventually to discuss the most natural approach to this problem, which is to use a Bayesian strategy (though we will be interested in it for other reasons). Meanwhile, there are modifications of UCB that treat the actions asymmetrically so that its regret is small if some arms are optimal and large otherwise.
We simply refer the interested reader to a paper on the Pareto regret frontier for bandits, which fully characterizes the trade-offs available to asymmetric algorithms in terms of the worst-case expected regret when comparing to a fixed arm.
Note 2. The leading constant in the instance dependent bound is sub-optimal. This can be improved by a more careful choice of $\lambda$ that is closer to $\Delta_i$ than $2\Delta_i$ and dealing with the lower-order terms that this introduces.

Hello, I always thanks you for these posting!
However, I have on question.
you wrote like this:
“in fact, it follows from our previous analysis that for sufficiently large n, UCB will achieve a regret of ∑i:Δi(ν)>0Clog(n)Δi(ν)≈CKlog(n), where Δi(ν) is the suboptimality gap of action i in ν”
Before saying this, you wrote on v the immediate regret(Δ) is close to 1. But in upper statement, you took Δ ≈1/K. I wonder Δ is not close to 1. What do you say?
I have read your posts on and on and I found one mistake.
c*(n) -> c*(v)
Since UCB is consistent for E′K⊃E′K(N),
c∗(ν)=infπ∈Πcons(E′K(N))lim infn→∞Rn(π,ν)log(n)≤lim supn→∞Rn(UCB,ν)log(n)≤c∗(n)
(anyway, I have wondered how can I write some equations like you)
In addition, you said p>=1 but you wrote ” Since p>0 was arbitrary, it follows that this also holds for p=0. ” why p=0??????????????
I misunderstood. So it is solved. Instead, how did you get the regret bound of UCBWaste C′√(Kn/2)? Assume non-optimal arms are only chosen in first m= C′√(Kn), then on average the number of choice with each non-optimal arms are C′√(n/K). So, I think regret is at least C′√(n/K) *the number of non-optimal arms on average(=K/2) * Δ ≈ C′√(Kn/4). Is it wrong?
Hello, I have one question, about (10) you wrote ” Second, even when Δi are all relatively large, the leading term in this lower bound is approximately half that of c∗(ν)”
But c*(v)’s leading term is 2 and (10)’s leading term of lower bound is 1/4 so they are different about 8 times! How can we say UCB is almost optimal? 8 times difference is trivial?
In the equation below “Theorem (Asymptotic lower bound for Gaussian environments)” the rhs has a $\leq c^\ast(n)$ but it should be $\leq c^\ast(\nu)$
I think there is another typo. Where it says:
“Indeed, since $i$ is suboptimal in $\nu$ and $i$ is optimal in $\nu’$ and for any $j\neq i$, $\Delta_j'(\nu) \geq \lambda – \Delta_i$”
It should be (prime in the last inequality is wrong)
“Indeed, since $i$ is suboptimal in $\nu$ and $i$ is optimal in $\nu’$ and for any $j\neq i$, $\Delta_j(\nu’) \geq \lambda – \Delta_i$”