
In the next few posts we will consider adversarial linear bandits, which, up to a crude first approximation, can be thought of as the adversarial version of stochastic linear bandits. The discussion of the exact nature of the relationship between adversarial and stochastic linear bandits is postponed until a later post. In the present post we consider only the the finite action case with $K$ actions.
The model
The learner is given a finite action set $\cA\subset \R^d$ and the number of rounds $n$. An instance of the adversarial problem is a sequence of loss vectors $y_1,\dots,y_n$ where for each $t\in [n]$, $y_t\in \R^d$ (as usual in the adversarial setting, it is convenient to switch to losses). Our standing assumption will be that the scalar loss for any of the action is in $[-1,1]$:
Assumption (bounded loss): The losses are such that for any $t\in [n]$ and action $a\in \cA$, $| \ip{a,y_t} | \le 1$.
As usual, in each round $t$ the learner selects an action $A_t \in \cA$ and receives and observes a loss $Y_t = \ip{A_t,y_t}$. The learner does not observe the loss vector $y_t$ (if the loss vector is observed, then we call it the full information setting, but this is a topic for another blog). The regret of the learner after $n$ rounds is
\begin{align*}
R_n = \EE{\sum_{t=1}^n Y_t} – \min_{a\in \cA} \sum_{t=1}^n \ip{a,y_t}\,.
\end{align*}
Clearly the finite-armed adversarial bandit framework discussed in a previous post is a special case of adversarial linear bandits corresponding to the choice $\cA = \{e_1,\dots,e_d\}$ where $e_1,\dots,e_d$ are the unit vectors of the $d$-dimensional standard Euclidean basis. The strategy will also be an adaptation of the exponential weights strategy that was so effective in the standard finite-action adversarial bandit problem.
Strategy
As noted, we will adapt the exponential weights algorithm. Like in that setting we need a way to estimate the individual losses for each action, but now we make use of the linear structure to share information between the arms and decrease the variance of our estimators. Let $t\in [n]$ be the index of the current round. Assuming that the loss estimates for action $a\in \cA$ are $(\hat Y_s(a))_{s < t}$, the distribution that the exponential weights algorithm proposes is
\begin{align*}
\tilde P_t(a) = \frac{ \exp\left( -\eta \hat \sum_{s=1}^{t-1} \hat Y_s(a) \right)}
{\sum_{a’\in \cA} \exp\left( -\eta \hat \sum_{s=1}^{t-1} \hat Y_s(a’) \right)}\,,
\qquad a\in \cA
\end{align*}
To control the variance of the loss estimates, it will be useful to mix this distribution with an exploration distribution, which we will denote by $\pi$. In particular, $\pi: \cA \to [0,1]$ with $\sum_a\pi(a)=1$. The mixture distribution is
\begin{align*}
P_t(a) = (1-\gamma) \tilde P_t(a) + \gamma \pi(a)\,,
\end{align*}
where $\gamma$ is a constant mixing factor to be chosen later. Then, in round $t$, the algorithm draws an action from $P_t$:
\begin{align*}
A_t \sim P_t(\cdot)\,.
\end{align*}
Recall that $Y_t = \ip{A_t,y_t}$ is the observed loss after taking action $A_t$. The next question is how to estimate $y_t(a) \doteq \ip{a,y_t}$? The idea will be to estimate $y_t$ with some vector $\hat Y_t\in \R^d$ and then letting $\hat Y_t(a) = \ip{a,\hat Y_t}$.
It remains to construct $\hat Y_t$. For this we will use the least-squares estimator $\hat Y_t = R_t A_t Y_t$, where $R_t$ is selected so that $\hat Y_t$ is an unbiased estimate of $y_t$ given the history. In particular, letting $\E_t[X] = \EE{ X \,|\, A_1,\dots,A_{t-1} }$, we calculate
\begin{align*}
\E_t [\hat Y_t ] = R_t \E_t [ A_t A_t^\top ] y = R_t \underbrace{\left(\sum_a P_t(a) a a^\top\right)}_{Q_t} y\,.
\end{align*}
Hence, using $R_t = Q_t^{-1}$, we get $\E_t [ \hat Y_t ] = y$. There is one minor technical detail, which is that $Q_t$ should be non-singular. This means that both the action set $\cA$ and the support of $P_t$ must span $\R^d$. To ensure this is true we will simply assume that $\cA$ spans $\R^d$ and eventually we will choose $P_t$ in such a way that its span is indeed $\R^d$. The assumption that $\cA$ spans $\R^d$ is non-restrictive, since if not we can simply adjust the coordinate system and reduce the dimension.
To summarize, in each round $t$ the algorithm estimates the unknown loss vector $\hat Y_t$ using the least-squares estimator, which is then used to directly estimate the loss for each action.
\begin{align*}
\hat Y_t = Q_t^{-1} A_t Y_t\,,\qquad \hat Y_t(a) = \ip{a,\hat Y_t}\,.
\end{align*}
Given the loss estimates all that remains is to apply the exponential weights algorithm with an appropriate exploration distribution and we will be done. Of course, the devil is in the details, as we shall see.
Regret analysis
By modifying our previous regret proof and assuming that for each $t\in [n]$,
\begin{align}
\label{eq:exp2constraint}
\eta \hat Y_t(a) \ge -1, \qquad \forall a\in \cA\,,
\end{align}
then the regret is bounded by
\begin{align}
R_n \le \frac{\log K}{\eta} + 2\gamma n + \eta \sum_t \EE{ \sum_a P_t(a) \hat Y_t^2(a) }\,.
\label{eq:advlinbanditbasicregretbound}
\end{align}
Note that we cannot use the proof that leads to the tighter constant ($\eta$ getting replaced by $\eta/2$ in the second term above) because there is no guarantee that the loss estimates will be upper bounded by one. To get a regret bound it remains to set $\gamma, \eta$ so that \eqref{eq:exp2constraint} is satisfied, and we also need to bound $\EE{ \sum_a P_t(a) \hat Y_t^2(a) }$. We start with the latter. Let $M_t = \sum_a P_t(a) \hat Y_t^2(a)$. Since
\begin{align*}
\hat Y_t^2(a) = (a^\top Q_t^{-1} A_t Y_t)^2 = Y_t^2 A_t^\top Q_t^{-1} a a^\top Q_t^{-1} A_t\,,
\end{align*}
we have $M_t = \sum_a P_t(a) \hat Y_t^2(a) = Y_t^2 A_t^\top Q_t^{-1} A_t\le A_t^\top Q_t^{-1} A_t$ and so
\begin{align*}
\E_t[ M_t ] \le \trace \left(\sum_a P_t(a) a a^\top Q_t^{-1} \right) = d\,.
\end{align*}
It remains to choose $\gamma$ and $\eta$. To begin, we strengthen \eqref{eq:exp2constraint} to $|\eta \hat Y_t(a) | \le 1$ and note that since $|Y_t| \leq 1$,
\begin{align*}
|\eta \hat Y_t(a) | = |\eta a^\top Q_t^{-1} A_t Y_t| \le \eta |a^\top Q_t^{-1} A_t|\,.
\end{align*}
Let $Q(\pi) = \sum_{\nu \in \cA} \pi(\nu) \nu \nu^\top$, then $Q_t \succ \gamma Q(\pi)$ and so by Cauchy-Schwartz we have
\begin{align*}
|a^\top Q_t^{-1} A_t| \leq \norm{a}_{Q_t^{-1}} \norm{A_t}_{Q_t^{-1}}
\leq \max_{\nu \in \cA} \nu^\top Q_t^{-1} \nu \leq \frac{1}{\gamma}\max_{\nu \in \cA} \nu^\top Q^{-1}(\pi) \nu\,,
\end{align*}
which implies that
\begin{align*}
|\eta \hat Y_t(a)| \leq \frac{\eta}{\gamma} \max_{\nu \in \cA} \nu^\top Q^{-1}(\pi)\nu\,.
\end{align*}
Since this quantity only depends on the action set and the choice of $\pi$, we can make it small by solving a design problem.
\begin{align}
\begin{split}
\text{Find a sampling distribution } \pi \text{ to minimize } \\
\max_{v \in \cA} v^\top Q^{-1}(\pi) v\,.
\end{split}
\label{eq:adlinbanditoptpbl}
\end{align}
If $D$ is the optimal value of the above minimization problem, the constraint \eqref{eq:exp2constraint} will hold whenever $\eta D \le \gamma$. This suggests choosing $\gamma = \eta D$ since \eqref{eq:advlinbanditbasicregretbound} is minimized if we choose a smaller $\gamma$. Plugging into \eqref{eq:advlinbanditbasicregretbound}, we get
\begin{align*}
R_n \le \frac{\log K}{\eta} +\eta n(2D+d) = 2 \sqrt{ (2D+d) \log(K) n }\,,
\end{align*}
where for the last equality we chose $\eta$ to minimize the upper bound. Hence, it remains to calculate, or bound $D$. In particular, in the next section we will show that $D\le d$ (in fact, equality also holds), which leads to the following result:
Theorem (Worst-case regret of adversarial linear bandits):
Let $R_n$ be the expected regret of the exponential weights algorithm as described above. Then, for an appropriate choice of $\pi$ and an appropriate shifting of $\cA$, if the bounded-loss assumption holds for the shifted action set,
\begin{align*}
R_n \le 2 \sqrt{3dn \log(K)}\,.
\end{align*}
Optimal design, volume minimizing ellipsoids and John’s theorem
It remains to show that $D\le d$. For this we need to choose a norm and a distribution $\pi$ according to \eqref{eq:adlinbanditoptpbl}. Consider now the problem of choosing a distribution $\pi$ on $\cA$ to minimize
\begin{align}
g(\pi) \doteq \max_{v\in \cA} v^\top Q^{-1}(\pi) v\,.
\label{eq:gcrit}
\end{align}
This is known as the $G$-optimal design problem in statistics, studied by Kiefer and Wolfowitz in 1960. In statistics, more precisely, in optimal experiment design, $\pi$ would be called a “design”. A $G$-optimal design $\pi$ is the one that minimizes the maximum variance of least-squares predictions over the “design space” $\cA$ when the independent variables are chosen with frequencies proportional to the probabilities given by $\pi$ and the response follows a linear model with independent zero mean noise and constant variance. After all the work we have done for stochastic linear bandits, the reader hopefully does recognize that $v^\top Q^{-1}(\pi) v$ is indeed the variance of the prediction under a least-squares predictor.
Theorem (Kiefer-Wolfowitz, 1960): The following are equivalent:
- $\pi$ is a minimizer of $f(\pi)\doteq -\log \det Q(\pi)$;
- $\pi$ is a minimizer of $g$;
- $g(\pi) = d$.
So there we have it. $D = d$ (with equality!) and our proof of the theorem is complete. A disadvantage of this approach is that it is not very apparent from the above theorem what the optimal sampling distribution $\pi$ actually looks like. We now make an effort to clarify this, and to briefly discuss the computational issues.
Consider the first equivalent claim of the Kiefer-Wolfowitz result which concerns the problem of minimizing $-\log \det Q(\pi)$, which is also is known as the $D$-optimal design problem ($D$ after “determinant”). The criterion in $D$-optimal design can be given an information theoretic interpretation, but we will find it more useful to consider it from a geometric angle. For this, we will need to consider ellipsoids.
An ellipsoid $E$ with center zero (“central ellipsoid”) is simply the image of the unit ball $B_2^d$ under some nonsingular linear map $L$: $E = L B_2^d$ where for a set $S\subset \R^d$, $LS = \{Lx \,:x\in S\}$. Let $H= (LL^\top)^{-1}$. Then, for any vector $y\in E$, $L^{-1}y\in B_2^d$, or $\norm{L^{-1}y}_2^2 = \norm{y}_{H}^2 \le 1$. We shall denote the ellipsoid $LB_2^d$ by $E(0,H)$ (the $0$ signifies that the center of the ellipsoid is at zero). Now $\vol(E(0,H)) = |\det L| \vol(B_2^d) = \mathrm{const}(d)/\sqrt{\det H} = \exp(\mathrm{const}(d) – \frac12 \log \det H)$. Hence, minimizing $-\log \det Q(\pi)$ is equivalent to maximizing the volume of the ellipsoid $E(0,Q^{-1}(\pi))$. By convex duality, one can then show that this is exactly the same problem as minimizing the volume of the central ellipsoid $E(0,H)$ that contains $\cA$. Fritz John’s celebrated result, which concerns minimum-volume enclosing ellipsoids (MVEEs) with no restriction on their center, gives the missing piece:
John’s theorem (1948): Let $\cK\subset \R^d$ be convex, closed and assume that $\mathrm{span}(\cK) = \R^d$. Then there exists a unique MVEE of $\cK$. Furthermore, this MVEE is the unit ball $B_2^d$ if and only if there exists $m\in \N$ contact points (“the core set”) $u_1,\dots,u_m$ that belong to both $\cK$ and the surface of $B_2^d$ and there also exist positive reals $c_1,\dots, c_m$ such that
\begin{align}
\sum_i c_i u_i=0 \quad \text{ and } \quad \sum_i c_i u_i u_i^\top = I.
\label{eq:johncond}
\end{align}
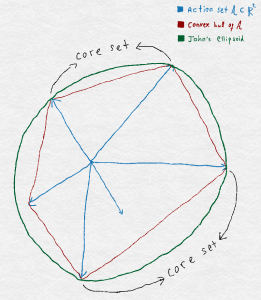
John’s Ellipsoid and the core set
Note that John’s theorem allows the center of the MVEE to be arbitrary. Again, by shifting the set $\cK$, we can always arrange for the center to be at zero. So how can we use this result? Let $\cK = \co(\cA)$ be the convex hull of $\cA$ and let $E = L B_2^d$ be its MVEE with some nonsingular $L$. Without loss of generality, we can shift $\cA$ to allow that the center of this MVEE to be at zero (why? actually, here we lose a factor of two: think of the bounded reward condition).
To pick $\pi$, note that the MVEE of $L^{-1} \cK$ is $L^{-1} L B_2^d = B_2^d$. Hence, by the above result, there exists $u_1,\dots,u_m\in L^{-1}\cK \cap \partial B_2^d$ and positive reals $c_1,\cdots,c_m$ such that \eqref{eq:johncond} holds. Note that $u_1,\dots,u_m$ must also be elements of $L^{-1} cA$ (why?). Therefore, $Lu_1,\dots,L u_m\in \cA \cap \partial E$. Thanks to the rotation property of the trace and that $\norm{u_i}_2 = 1$, taking the trace of the second equality in \eqref{eq:johncond} we see that $\sum_i c_i = d$. Hence, we can choose $\pi(L u_i) = c_i/d$, $i\in [m]$ and set $\pi(a)=0$ for all $a\in \cA \setminus \{ L u_1,\dots, L u_m \}$. Therefore
\begin{align*}
Q(\pi) = \frac{1}{d} L \left(\sum_i c_i u_i u_i^\top \right) L^\top = \frac{1}{d} L L^\top\,
\end{align*}
and so
\begin{align}
\sup_{v \in \cA} v^\top Q^{-1}(\pi) v
\leq \sup_{v\in E=LB_2^d} v^\top Q^{-1}(\pi) v
= d \sup_{u: \norm{u}_2\le 1} (L u)^\top (L L^\top)^{-1} (L u) = d\,.
\label{eq:ellipsoiddesign}
\end{align}
Notes and departing thoughts
Note 1: In linear algebra, a frame of a vector space $V$ with an inner product can be seen as a generalization of the idea of a basis to sets which may be linearly dependent. In particular, given $0A<B<+\infty$, the vectors $v_1,\dots,v_m \in V$ is said to form an $(A,B)$-frame in $V$ if for any $x\in V$, $A\norm{x}^2 \le \sum_k |\ip{x,v_k}|^2 \le B \norm{x}^2$ where $\norm{x}^2 = \ip{x,x}$. Here, $A$ and $B$ are called the lower and upper frame bounds. When $\{v_1,\dots,v_m\}$ forms a frame, it must span $V$ (why?). However, $\span(\{v_1,\dots,v_m\}) = V$ is not a sufficient condition for $\{v_1,\dots,v_m\}$ to be a frame. The frame is called tight if $A=B$ and in this case the frame obeys a generalized
Parseval’s identity. If $A = B = 1$ then the frame is called Parseval or normalized. A frame can be used almost as a basis. John’s theorem can be seen as asserting that for any convex body, after an appropriate affine transformation of the body, there exist a tight frame inside the transformed convex body. Indeed, if $u_1,\dots,u_m$ are the vectors whose existence is guaranteed by John’s theorem and $\{c_i\}$ are the corresponding coefficients, $v_i = \sqrt{c_i/d}\, u_i$ will form a tight frame inside $\cK$. Given a frame $\{v_1,\dots,v_m\}$ and a given point $x\in V$ if we define $\norm{x}^2 \doteq \sum_k |\ip{x,v_k}|^2$, this is indeed a norm. For the frame coming from John’s theorem, for any $x\in \cK$, $\norm{x}^2\le 1$. Frames are widely used in harminoc (e.g., wavelet) analysis.
Note 2: The prediction with expert advice problem can also be framed as a linear prediction problem with changing action sets. In this generalization in every round the learner is given $M$ vectors, $a_{1t},\dots,a_{Mt}\in \R^d$, where $a_{it}$ is the recommendation of expert $i$. The environment’s choice for the round is $y_t\in \R^d$. The loss suffered by expert $i$ is $\ip{a_{it},y_t}$. The goal is to compete with the best expert in advice by selecting in every round based on past information one of the experts. If $A_t\in \{a_{1t},\dots,a_{Mt}\}$ is the vector recommended by the expert selected, the regret is
\begin{align*}
R_n = \EE{ \sum_{t=1}^n \ip{A_t,y_t} } – \min_{i\in [M]} \sum_{t=1}^n \ip{ a_{it}, y_t }\,.
\end{align*}
The algorithm discussed can be easily adapted to this case. The only change needed is that in every round one needs to choose a new exploration distribution $\pi_t$ that is adapted to the current “action set” $\cA_t = \{ a_{1t},\dots,a_{Mt} \}$. The regret bound proved still holds for this case. The setting of Exp4 discussed earlier corresponds to when $\cA_t$ is the subset of the $d$-dimensional simplex. The price of the increased generality of the current result is that while Exp4 enjoyed (in the notation of the current post) a regret of $\sqrt{2n (M \wedge d) \log(M) }$, here we would get on $O(\sqrt{n d \log(M)})$ with slightly higher constants.
Note 3 (Computation): The computation of the MVEE is a convex problem when the center of the ellipsoid is fixed and numerous algorithms have been developed for it, enjoying polynomial runtime guarantees exist. In general, the computation of the MVEE is hard. The approximate computation of optimal design is also widely researched; one can use, e.g., the so-called Franke-Wolfe algorithm for this purpose, which is known as Wynn’s method in optimal experimental design. John has also shown (implicitly) that the cardinality of the core set is at most $d(d+3)/2$.
References
Using John’s theorem for guiding exploration in linear bandits was proposed by
- Sébastien Bubeck, Nicolò Cesa-Bianchi, Sham M. Kakade:
Towards Minimax Policies for Online Linear Optimization with Bandit Feedback. COLT 2012: 41.1-41.14
where the exponential weights algorithm adopted to this setting is called Expanded Exp, or Exp2. Our proof departs from the proofs given here in some minor ways (we tried to make the argument a bit more pedagogical).
The review work
- Sébastien Bubeck and Nicolò Cesa-Bianchi (2012), “Regret Analysis of Stochastic and Nonstochastic Multi-armed Bandit Problems“, Foundations and Trends in Machine Learning: Vol. 5: No. 1, pp 1-122
also discussed Exp2.
According to our best knowledge, the connection to optimal experimental design through the Kiefer-Wolfowitz theorem and the proof that solely relied on this result has not been pointed out in the literature beforehand, though the connection between the Kiefer-Wolfowitz theorem and MVEEs is well known. It is discussed, for example in the recent nice book of Michael J. Todd
- Michael J. Todd: Minimum-Volume Ellipsoids: Theory and Algorithms, MOS-SIAM Series on Optimization, 2016.
This book also discusses algorithmic issues, the mentioned duality.
The theorem of Kiefer and Wolfowitz is due to them:
- J. Kiefer and J. Wolfowitz. The equivalence of two extremum problems. Canadian Journal of Mathematics, 12:363–366, 1960
John’s theorem is due to John Fritz:
- F. John. Extremum problems with inequalities as subsidiary conditions. In Studies and Essays, presented to R. Courant on his 60th birthday, January 8, 1948, pages 187–204. Interscience, New York, 1948.
The duality mentioned in the text was proved by Siber:
- R. Sibson. Discussion on the papers by Wynn and Laycock. Journal of the Royal Statistical Society, 34:181–183, 1972.
See also:
- F. Gürtuna. Duality of ellipsoidal approximations via semi-infinite programming. SIAM Journal on Optimization, 20:1421–1438, 2009.
Finally, one need not find the exact optimal solution to the design problem. An approximation up to reasonable accuracy is sufficient for small regret. The issues of finding a good exploration distribution efficiently (even in infinite action sets) are addressed in

Test comment