
In the last two posts we considered stochastic linear bandits, when the actions are vectors in the $d$-dimensional Euclidean space. According to our previous calculations, under the condition that the expected reward of all the actions are in a fixed bounded range (say, [-1,1]), the regret of Ellipsodial-UCB is $\tilde O(d \sqrt{n} )$ ($\tilde O(\cdot)$ hides logarithmic factors). This is definitely an advance when the number of actions $K$ is much larger than $d$, but $d$ itself can be quite large in some applications. In particular, in contextual bandits $d$ would be the dimension of the feature space that the actions are mapped into. The previous result indicates that there is a high price to be paid for having more features. This is not what we want. Ideally, one should be able to “add features” without suffering much additional regret if the feature added does not contribute in a significant way. This can be captured by the notion of sparsity, which is the central theme of this post.
Sparse linear stochastic bandits
The sparse linear stochastic bandit problem is the same as the stochastic linear bandit problem with a small difference. Just like in the standard setting, at the beginning of a round with index $t\in \N$ the learner receives a decision set $\cD_t\subset \R^d$. Let $A_t\in \cD_t$ be the action chosen by the learner based on the information available to it. The learner then receives the reward
\begin{align}
X_t = \ip{A_t,\theta_*} + \eta_t\,,
\label{eq:splinmodel}
\end{align}
where $(\eta_t)_t$ is zero-mean noise (subject to the usual subgaussianity assumption) and $\theta_*\in \R^d$ is an unknown vector. The specialty of the sparse setting is that the parameter vector $\theta_*$ is assumed to have many zero entries. Introducing the “$0$-norm”
\begin{align*}
\norm{\theta_*}_0 = \sum_{i=1}^d \one{ \theta_{*,i}\ne 0 }\,,
\end{align*}
the assumption is that
\begin{align*}
p \doteq \norm{\theta_*}_0 \ll d\,.
\end{align*}
Much ink has been spilled on what can be said about the speed of learning in linear models like (\ref{eq:splinmodel}) when $\{A_t\}_t$ are passively generated and the parameter vector is known to be sparse. Most results are phrased about recovering $\theta_*$, but there also exist a few results that quantify the speed at which good predictions can be made. The ideal outcome would be that the learning speed depends mostly on $p$, while the dependence on $d$ becomes less severe (e.g., the learning speed is a function of $p \log(d)$). Almost all the results come under the assumption that the vectors $\{A_t\}_t$ are “incoherent”, which means that the Grammian underlying $A_t$ should have good conditioning. The details are a bit more complicated, but the main point is that these conditions are exactly what the action vector resulting from a good bandit algorithm will not satisfy: Bandit algorithms want to choose the optimal action as often as possible, while for standard theory on fast learning under sparsity one needs all directions of the space to be thoroughly explored. We need some approach that does not rely on such strong assumptions.
Elimination on the hypercube
As a warmup problem consider linear bandits when the decision set (of every round) is the $d$-dimensional hypercube: $\cD = [-1,1]^d$. To reduce clutter we will denote the “true” parameter vector by $\theta$. Thus, in every round $t$, $X_t = \ip{A_t,\theta_t}+\eta_t$. We assume that $\eta_t$ is conditionally $1$-subgaussian given the past:
\begin{align*}
\EE{ \exp(\lambda \eta_t ) | \cF_{t-1} } \le \exp( \frac{\lambda^2}{2} ) \quad \text{for all } \lambda \in \R\,.
\end{align*}
Here $\cF_{t-1} = \sigma( A_1,X_1,\dots,A_{t-1},X_{t-1}, A_t )$. Since conditional subgaussanity comes up frequently, we introduce a notation for it: When $X$ is $\sigma^2$ subgaussian given some $\sigma$-field $\cF$ we will write $X|\cF \sim \subG(\sigma^2)$. Our earlier statement that the sum of independent subgaussian random variables is subgaussian with a subgaussianity factor that is the sum of the two factors also holds for conditionally subgaussian random variables.
We shall also assume that the mean rewards lie in the range $[-1,1]$. That is, $|\ip{a,\theta}|\le 1$ for all $a\in \cD$. Note that this is equivalent to $\norm{\theta}_1\le 1$.
Stochastic linear bandits on the hypercube is notable as it enjoys perfect “separability”: For each dimension $i\in [d]$, $A_{ti}$ can be selected regardless of the choice of $A_{tj}$ for the other dimensions $j\ne i$. It follows among other things that the optimal action can be computed dimension-wise. In particular, the optimal action for dimension $i$ is simply the sign of $\theta_i$. This is good and bad news. In the worst case, this structure means that each sign has to be learned independently. As we shall see later this implies that in the worst case the regret will be as large as $\Omega(d\sqrt{n})$ (our next post will expand on this). However, the separable structure is also good news: An algorithm can estimate $\theta_i$ for each dimension separately while paying absolutely no price for this experimentation when $\theta_i=0$ (because the choice of $A_{ti}$ does not restrict the choice of $A_{tj}$ with $j\ne i$). As we shall see, because of this we can design an algorithm whose regret scales with $O(\norm{\theta}_0\sqrt{n})$ even without knowing the value of $\norm{\theta}_0$.
The algorithm that achieves this is a randomized variant of Explore then Commit. For reasons that will become clear, we will call it “Selective Explore then Commit” or SETC. The algorithm works as follows: SETC keeps an interval-estimate $U_{ti}\subset \R$ of all components $\theta_i$. These will be constructed such that $\theta_i$ is contained in $\cap_{t\in [n]} U_{ti}$ with high probability (for simplicity we assume that a horizon $n$ is given to the algorithm; lifting this assumption is left as an exercise to the reader).
Assume for a moment that we are given intervals $(U_{ti})_{t}$ that contain $\theta_i$ with high probability. Consider the event when the intervals actually do contain $\theta_i$. If at some point $t$ it holds that $0\not \in U_{ti}$, then the sign of $\theta_i$ can be determined by examining on which size of $0$ the interval $U_{ti}$ falls, which allows us to set $A_{ti}$ optimally! In particular, if $U_{ti}\subset (0,\infty)$ then $\theta_i>0$ must hold and we will set $A_{ti}$ to $1$, while if $U_{ti}\subset (-\infty,0)$ then $\theta_i<0$ must hold and we set $A_{ti}$ to $-1$. On the other hand, if at some round $t$, $0\in U_{ti}$ then the sign of $\theta_i$ is uncertain and more information needs to be collected on $\theta_i$, i.e., one needs more exploration.In this case, to maximize the information gained, $A_{ti}$ can be chosen at random to be either $1$ or $-1$ with equal probabilities (a random variable that takes on values of $+1$ and $-1$ with equal probabilities is called a Rademacher random variable with parameter $0.5$). This leads to new information from which $U_{ti}$ can be refined (when no exploration is needed, $U_{ti}$ is not updated: $U_{t+1,i} = U_{ti}$). The algorithm, as far as the choice of $A_{ti}$ is concerned is summarized on the figure shown below.
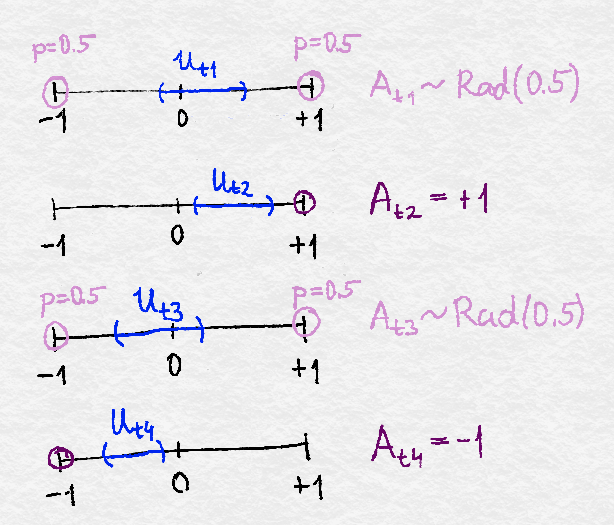
The action choices in the SETC algorithm. In each dimension $i$ an interval is kept that holds $\theta_i$ with high probability. If the interval for a given dimension does not contain $0$, the action for that dimension is chosen as $+1$ or $-1$ depending on which side of zero the interval is. When the interval contains zero, the action is selected at random to be $+1$ or $-1$ with equal probabilities. In this, and only in this case the interval for $\theta_i$ is updated. For a detailed explanation, see the text.
To derive the form of $U_{t+1,i}$ consider $A_{ti} X_t$, the correlation of $A_{ti}$ and the reward observed. Expanding on the definition of $X_t$, using that $A_{ti}^2=1$, we see that
\begin{align*}
A_{ti} X_t = \theta_i + \underbrace{A_{ti} \sum_{j\ne i} A_{tj} \theta_j + A_{ti} \eta_t}_{Z_{ti}}\,.
\end{align*}
This suggests to set
\begin{align*}
\hat \theta_{ti} = \frac1t \sum_{s=1}^t A_{si} X_s\,,\quad
c_{ti} = 2\sqrt{ \frac{ \log(2n^2)}{t} }\, \text { and }\,\,
U_{t+1,i} = [\hat \theta_{ti} – c_{ti}, \hat \theta_{ti} + c_{ti} ]\,.
\end{align*}
To explain the choice of $c_{ti}$ we need a version of our the subgaussian concentration inequality which was stated for independent sequences of subgaussian random variables. In our case $(Z_{ti})_t$, as we shall soon see, are conditionally subgaussian. Using Chernoff’s method it is not hard to prove the following result:
Lemma (Hoeffding-Azuma): Let $\cF\doteq (\cF_t)_{0\le t\le n}$ be a filtration, $(Z_t)_{t\in [n]}$ be an $\cF$-adapted martingale difference sequence such that $Z_t$ is conditionally $\sigma^2$-subgaussian given $\cF_{t-1}$: $Z_t|\cF_{t-1} \sim \subG(\sigma^2)$. Then, $\sum_{t=1}^n Z_t$ is $n\sigma^2$ subgaussian and for any $\eps>0$,
\begin{align*}
\Prob{ \sum_{t=1}^n Z_t \ge \eps } \le \exp( – \frac{ \eps^2}{2n\sigma^2} )\,.
\end{align*}
Proof: Let $S_t = \sum_{s=1}^t Z_t$ with $S_0 = 0$. It suffices to show that $S_n$ is $n\sigma^2$ subgaussian. To show this, note that for $t\ge 1$, $\lambda\in \R$,
\begin{align*}
\EE{ \exp(\lambda S_t) } = \EE{\exp(\lambda S_{t-1}) \EE{ \exp(\lambda Z_t) | \cF_{t-1}} } \le \exp(\frac{\lambda^2\sigma^2}{2}) \EE{ \exp(\lambda S_{t-1}) }\,.
\end{align*}
Since $\exp(\lambda S_0)=1$, chaining the inequalities obtained we get the desired bound.
QED.
Sometimes, it is more convenient to use the “deviation” form of the above inequality which states that for any $\delta\in (0,1)$, with probability $1-\delta$,
\begin{align*}
\sum_{t=1}^n Z_t \le \sqrt{ 2 n \sigma^2 \log(1/\delta) }\,.
\end{align*}
The Hoeffding-Azuma inequality together with some union bounds leads to the following lemma:
Lemma (Reliable Intervals): Let $F_i = \{ \exists t\in [n] \text{ s.t. } \theta_i \not \in U_{ti} \}$ be the “failure” event that some of the intervals $U_{ti}$ fails to include $\theta_i$. Then,
\begin{align*}
\Prob{F_i} \le \frac{1}{n}\,.
\end{align*}
The proof will be provided at the end of the section.
Let $R_{ni} = n|\theta_i|-\EE{\sum_{t=1}^n A_{ti}\theta_i }$ and let $R_n = \max_{a\in \cD} n \ip{a,\theta} – \EE{ \sum_{t=1}^n \ip{A_t,\theta}}$ be the regret of SETC. Then, $R_n = \sum_{i:\theta_i\ne 0} R_{ni}$. Hence, it suffices to bound $R_{ni}$ for $i$ such that $\theta_i\ne 0$. Now, when the confidence intervals for dimension $i$ do not fail, i.e., on $F^c_{ni}$, the regret is at most $2|\theta_i| \tau_i$ where $\tau_i = \sum_{s=1}^n E_{si} $ is the number of exploration steps for dimension $i$. On the same event, we claim that $\tau_i\le 1 + 16 \log(2n^2)/|\theta_i|^2$ also holds. To see this it is enough to show that $\tau_i \le t$ for any $t>t_0\doteq 16 \log(2n^2) / |\theta_i|^2$. Pick such a $t$ and observe that $t>t_0$ is equivalent to $4 \sqrt{ \log(2n^2)/t} < | \theta_i|$. By definition, $c_{ti} = 2 \sqrt{ \log(2n^2)/(\tau_i\wedge t) }$. If $\tau_i\le t$ there is nothing to be proven. Hence, assume that $\tau_i>t$. Then, $\tau_i \wedge t = t$ and thus we get that $2c_{ti}<|\theta_i|$. Then, $|\hat \theta_{ti} | – c_{ti} \ge |\theta_i| – 2c_{ti}>0$, where the first inequality follows from that $|\theta_i-\hat\theta_{ti}|\le c_{ti}$. Since $|\hat \theta_{ti}|-c_{ti}>0$, $0\not\in U_{ti}$ and hence $E_{t+1,i}=\dots = E_{ni}=0$, which implies that $\tau_i\le t$, which contradicts with $\tau_i>t$, finishing the proof. Putting things together we get
\begin{align*}
R_{ni}
& = \EE{ \one{F_i} \sum_{t=1}^n (\sgn(\theta_i)-A_{ti}) \theta_i }
+ \EE{ \one{F_i^c} \sum_{t=1}^n (\sgn(\theta_i)-A_{ti}) \theta_i }\\
& \le 2n |\theta_i| \Prob{F_i} + \EE{ \one{F_i^c} 2|\theta_i| \tau_i } \\
& \le 2n|\theta_i| \Prob{F_i} + |\theta_i| (1+ \frac{16 \log(2n^2) }{|\theta_i|^2}) \\
&= 3|\theta_i| + \frac{16 \log(2n^2) }{|\theta_i|}\,,
\end{align*}
yielding the following theorem:
Theorem (Regret of SETC): Let $\norm{\theta}_1\le 1$. Then, the regret $R_n$ of SETC satisfies
\begin{align*}
R_n \le 3 \norm{\theta}_1 + 16 \sum_{i:\theta_i\ne 0} \frac{\log(2n^2) }{|\theta_i|}\,.
\end{align*}
Since $R_{ni} \le 2 n |\theta_i|$ also holds, we immediately get a bound on the worst-case regret of SETC for $p$-sparse vectors:
Corollary (Worst-case regret of SETC): Let $n\ge 2$. The minimax regret of SETC $R_n^*$ over $\norm{\theta}_1\le 1$, $\norm{\theta}_0\le p$ satisfies
\begin{align*}
R_n \le 3p + 8 p \sqrt{ n \log(2n^2)} \,.
\end{align*}
Thus we see that SETC successfully trades the dimension $d$ for the sparsity index $p$ without ever needing the knowledge of $p$. This should be encouraging! Can this result be generalized beyond the hypercube? This is the question we investigate next.
However, we first finish the proof of the theorem by providing the proof of the lemma that claimed that the event $F_i$ has a small probability.
Proof of $\Prob{F_i}\le 1/n$.
Proof: Setting $\cF_t = \sigma(A_1,X_1,\dots,A_t,X_t)$, we see that $(Z_{ti})_t$ is $(\cF_t)_t$-adapted (note that $\cF_{t-1}$ now excludes $A_t$!). Letting $S_{ti} = \sum_{j\ne i} A_{tj} \theta_j$, we can write $Z_{ti} = A_{ti} S_{ti} + A_{ti}\eta_t$. We check that $Z_{ti}|\cF_{t-1}\sim \subG(2)$. With repeated conditioning we calculate
\begin{align*}
\EE{ \exp(\lambda Z_{ti} )|\cF_{t-1} }
&= \EE{ \EE{ \exp(\lambda Z_{ti} )|\cF_{t-1},A_t} |\cF_{t-1} } \\
&= \EE{ \exp(\lambda A_{ti} S_{ti} ) \EE{ \exp(\lambda A_{ti} \eta_t )|\cF_{t-1},A_t} |\cF_{t-1} } \\
&\le \EE{ \exp(\lambda A_{ti}S_{ti} ) \exp(\frac{\lambda^2}{2}) |\cF_{t-1} } \\
&= \exp(\frac{\lambda^2}{2})
\EE{ \EE{\exp(\lambda A_{ti} S_{ti} )|\cF_{t-1},S_{ti}} |\cF_{t-1} } \\
&\le \exp(\frac{\lambda^2}{2})
\EE{ \exp( \frac{\lambda^2 S_{ti}^2}{2} ) |\cF_{t-1} } \\
&\le \exp(\lambda^2)\,,
\end{align*}
where the first inequality used that $\eta_t$ and $A_t$ are conditionally independent given $\cF_{t-1}$ and that $\eta_t|\cF_{t-1}\sim \subG(1)$, the second to last inequality used that $S_{ti}$ and $A_{ti}$ are conditionally independent given $\cF_{t-1}$ and that $A_{ti}|\cF_{t-1}\sim \subG(1)$, the last step used that $|S_{ti}|\le 1$. From this, we conclude that $Z_{ti}|\cF_{t-1} \sim \subG(2)$. Let $E_{si}$ be the indicator of whether dimension $i$ is “explored” in round $s$. That is, $E_{si}\in \{0,1\}$ and $E_{si}=1$ iff dimension $i$ is explored in round $s$. Note that for any $t\in [n]$,
\begin{align*}
\hat \theta_{ti} = \frac{\sum_{s=1}^t E_{si} A_{si} X_s}{\sum_{s=1}^t E_{si}}\,,
\qquad
c_{ti} = 2\sqrt{ \frac{ \log(2n^2) }{ \sum_{s=1}^t E_{si} } }\,.
\end{align*}
Then,
\begin{align*}
\Prob{ \exists t\in [n] \,:\, \theta_i \not\in U_{ti} }
& \le \sum_{t=1}^n \Prob{ \theta_i \not\in U_{ti} } \\
& = \sum_{t=1}^n \Prob{ |\hat\theta_{ti} – \theta_i| > c_{ti} } \\
& = \sum_{t=1}^n \Prob{ \left| \sum_{s=1}^t E_{si} Z_{si} \right| > 2\sqrt{ (\sum_{s=1}^t E_{si}) \log(2n^2) } } \\
& = \sum_{t=1}^n
\sum_{p=1}^t
\Prob{ \left| \sum_{s=1}^t E_{si} Z_{si} \right| > 2\sqrt{ (\sum_{s=1}^t E_{si}) \log(2n^2) },
\sum_{s=1}^t E_{si}=p } \\
& \le \sum_{t=1}^n
\sum_{p=1}^t
\Prob{ \left| \sum_{s=1}^p E_{si} Z_{si} \right| > 2\sqrt{ p \log(2n^2) }
} \\
& \le \sum_{t=1}^n
\sum_{p=1}^t
\exp\left( \frac{4 p \log(2n^2)} { 2 (2p) } \right) =1/n\,.
\end{align*}
QED.
UCB with sparsity
Let us now tackle the question of how to exploit sparsity when there is no restriction on the action set $\cD_t$. The plan is to use UCB where the ellipsoidal confidence set used earlier is replaced by another confidence set, which is also ellipsoidal but has a smaller radius when the parameter vector is sparse.
Our starting point is the generic regret bound for UCB, which we replicate here for the reader’s convenience.
Let $A_t$ be the action chosen by UCB in round $t$: $A_t = \argmax_{a\in \cD_t} \UCB_t(a)$ where $\UCB_t(a)$ is the UCB index of action $a$ and $\cD_t\subset \R^d$ is the set of actions available in round $t$. Define
\begin{align}
V_t=V_0 + \sum_{s=1}^{t} A_s A_s^\top, \qquad t\in [n]\,,
\label{eq:sparselinbanditreggrammian}
\end{align}
where $V_0\succ 0$ is a fixed positive semidefinite matrix, which is often set to $\lambda I$ with some $\lambda>0$ tuning parameter. Let the following conditions hold:
- Bounded scalar mean reward: $|\ip{a,\theta_*}|\le 1$ for any $a\in \cup_t \cD_t$;
- Bounded actions: for any $a\in \cup_t \cD_t$, $\norm{a}_2 \le L$;
- Honest confidence intervals: With probability $1-\delta$, for all $t\in [n]$, $a\in \cD_t$, $\ip{a,\theta_*}\in [\UCB_t(a)-2\sqrt{\beta_{t-1}} \norm{a}_{V_{t-1}^{-1}},\UCB_t(a)]$ where $(V_{t})_t$ are given by \eqref{eq:sparselinbanditreggrammian}.
Our earlier generic result for UCB for linear bandits was as follows:
Theorem (Regret of UCB for Linear Bandits): Let the conditions listed above hold. Further, assume that $(\beta_t)_t$ is nondecreasing and $\beta_n\ge 1$. Then, with probability $1-\delta$, the pseudo-regret $\hat R_n = \sum_{t=1}^n \max_{a\in \cD_t} \ip{a,\theta_*} – \ip{A_t,\theta_*}$ of UCB satisfies
\begin{align*}
\hat R_n
% \le \sqrt{ 8 n \beta_{n-1} \, \log \frac{\det V_{n}}{ \det V_0 } }
\le \sqrt{ 8 d n \beta_{n-1} \, \log \frac{\trace(V_0)+n L^2}{ d\det V_0 } }\,.
\end{align*}
As noted earlier the half-width $\sqrt{\beta_{t-1}} \norm{a}_{V_{t-1}^{-1}}$ used in the assumption is the same as the one that we get when a confidence set $\cC_t$ is used which satisfies
\begin{align}
\cC_t \subset
\cE_t \doteq \{ \theta \in \R^d \,:\,
\norm{\theta-\hat \theta_{t-1}}_{ V_{t-1}}^2 \le \beta_{t-1} \}\,
\label{eq:ellconf}
\end{align}
with some $\hat \theta_{t-1}\in \R^d$. Our approach will be to identify some $\hat \theta_{t-1}$ and $\beta_{t-1}$ such that $\beta_{t-1}$ will scale with the sparsity of $\theta_*$.
In particular, we will prove the following result:
Theorem (Sparse Bandit UCB): There exist a strategy to compute the $\UCB_t(\cdot)$ indices such that the expected regret $R_n$ of the resulting policy satisfies $R_n = \tilde{O}(\sqrt{dpn})$.
Before presenting how this is done note that the best regret that we can hope to get is $\tilde{O}(\sqrt{ d n })$ with some additional terms depending on $p = \norm{\theta_*}_0$. This may be a bit disappointing. However, it is easy to see that the appearance of $d$ is the price one must pay for the increased generality of the result. In particular, we know that the regret for the standard $d$-action stochastic bandit problem is $\Omega(\sqrt{dn})$. Recall that $d$-action bandits can be represented as linear bandits with $\cD_t = \{e_1,\dots,e_d\}$ where $e_1,\dots,e_d$ is the standard Euclidean basis. Furthermore, checking the proof of the lower bound reveals that the proof uses $2$-sparse parameter vectors when rerepresented as linear bandits. Thus the appearance of $\sqrt{d}$, however unfortunate, is unavoidable in the general case. Later we will return to the question of lower bounds for sparse linear bandits.
Online to confidence set conversion
The idea of the construction that we present here is to build a confidence set around a prediction method that enjoys strong learning guarantees in the sparse case. The construction is actually generic and can be applied beyond sparse problems.
The prediction problem considered is online linear prediction where the prediction error is measured in the squared loss. This is also known as the online linear regression problem. In this problem setting a learner interacts with a strategic environment in a sequential manner in discrete rounds. In round $t\in \N$ the learner is first presented with a vector $A_t\in \R^d$ that is chosen by the environment ($A_t$ is allowed to depend on past choices of the learner) and the learner needs to produce a real-valued predictions $\hat X_t$, which is then compared to the target $X_t\in \R$ which is also chosen by the environment. The learner’s goal is to produce predictions whose total loss is not much worse than the loss suffered by any of the linear predictors in some set. The loss in a given round is the squared difference. The regret of the learner against a linear predictor that uses the “weights” $\theta\in \R^d$ is
\begin{align}
\rho_n(\theta) \doteq \sum_{t=1}^n (X_t – \hat X_t)^2 – \sum_{t=1}^n (X_t – \ip{A_t,\theta})^2
\label{eq:olrregretdef}
\end{align}
and we say that the learner enjoys a regret guarantee $B_n$ against some $\Theta \subset \R^d$ if no matter the environment’s strategy,
\begin{align*}
\sup_{\theta\in \Theta} \rho_n(\theta)\le B_n\,.
\end{align*}
The online learning literature in machine learning has a number of powerful algorithms for this learning problem with equally powerful regret guarantees. Later we will give a specific result for the sparse case.
Now take any learner for online linear regression and assume that the environment generates $X_t$ in a stochastic manner like in linear bandits:
\begin{align}
X_t = \ip{A_t,\theta_*} + \eta_t\,,
\label{eq:sparselbmodel234}
\end{align}
where $\eta_t|\cF_{t-1} \sim \subG(1)$ and $\cF_{t} = \sigma(A_1,X_1,\dots,A_t,X_t,A_{t+1})$. Observing that a confidence set $\theta_*$ is nothing but a constraint on $\theta_*$ in terms of known quantities, combining \eqref{eq:olrregretdef} and \eqref{eq:sparselbmodel234} by elementary algebra we derive
\begin{align}
\sum_t (\hat X_t – \ip{A_t,\theta_*})^2 = \rho_n(\theta_*) + 2 \sum_t \eta_t (\hat X_t – \ip{A_t,\theta_*})\,.
\label{eq:spb_regret_identity}
\end{align}
Let $Z_t = \sum_{s=1}^t \eta_t (\hat X_t – \ip{A_t,\theta_*})$ with $Z_0=0$. Since $\hat X_t$ is chosen based on information available at the beginning of round $t$, $\hat X_t$ is $\cF_{t-1}$-measurable. Hence, $(Z_t – Z_{t-1})| \cF_{t-1} \sim \subG( \sigma_t^2 )$ where $\sigma_t^2 = (\hat X_t – \ip{A_t,\theta_*})^2$. Now define $Q_t = \sum_{s=1}^t \sigma_t^2$. The uniform self-normalized tail bound at the end of our previous post implies that for any $u>0$ and any $\lambda>0$,
\begin{align*}
\Prob{ \exists t\ge 0 \text{ such that }
|Z_t| \ge \sqrt{ (\lambda+Q_t) \log \frac{(\lambda+Q_t)}{\delta^2\lambda} }
} \le \delta\,.
\end{align*}
Choose $\lambda=1$. On the event $\cE$ when $|Z_t|$ is bounded by $\sqrt{ (1+Q_t) \log \frac{(1+Q_t)}{\delta^2} }$, from \eqref{eq:spb_regret_identity} and $\rho_t(\theta_*)\le B_t$ we get
\begin{align*}
Q_t \le B_t + 2 \sqrt{ (1+Q_t) \log \frac{(1+Q_t)}{\delta^2} }\,.
\end{align*}
While both sides depend on $Q_t$, the left-hand side grows linearly, while the right-hand side grows sublinearly in $Q_t$. This means that the largest value of $Q_t$ that satisfies the above inequality is finite. A tedious calculation then shows this value must be less than
\begin{align}
\beta_t(\delta) \doteq 1 + 2 B_t + 32 \log\left( \frac{\sqrt{8}+\sqrt{1+B_t}}{\delta} \right)\,.
\label{eq:betadef}
\end{align}
As a result on $\cE$, $Q_t \le \beta_t(\delta)$, implying the following result:
Theorem (Sparse confidence set): Assume that for some strategy for online linear regression with $\theta\in \Theta$, $\rho_t(\theta)\le B_t$. Let $(A_t,X_t,\hat X_t)_t$, $(\cF_t)_t$ be such that $A_t,\hat X_t$ are $\cF_{t-1}$ measurable, $X_t$ is $\cF_{t}$-measurable and for some $\theta_*\in \Theta$, $X_t = \ip{A_t,\theta_*}+\eta_t$ where $\eta_t|\cF_{t-1}\sim \subG(1)$. Fix $\delta\in (0,1)$ and define
\begin{align*}
C_{t+1} = \{ \theta\in \R^d \,:\, \sum_{s=1}^t (\hat X_s – \ip{A_s,\theta})^2 \le \beta_t(\delta) \}\,.
\end{align*}
Then, $\Prob{ \exists t\in \N \text{ s.t. } \theta_* \not\in C_{t+1} }\le \delta$.
To recap, our online linear regression based UCB (OLR-UCB) in round $t$ works as follows. For specificity, let us call $\pi$ the online linear regression method.
- Receive the action set $\cD_t\subset \R^d$.
- Choose $A_t = \argmax_{a\in \cD_t} \max_{\theta\in C_t} \ip{a,\theta}$
- Feed $A_t$ to $\pi$ and get its prediction $\hat X_t$.
- Construct $C_{t+1}$ via the help of $A_t$ and $\hat X_t$.
- Receive the reward $X_t = \ip{A_t,\theta_*} + \eta_t$
- Feed $X_t$ to $\pi$ as feedback.
The set $C_{t+1}$ is an ellipsoid underlying the Grammian $V_t = I + \sum_{s=1}^t A_t A_t^\top$ and center
\begin{align*}
\hat \theta_t = \argmin_{\theta\in \R^d} \norm{\theta}_2^2 + \sum_{s=1}^t (\hat X_t – \ip{A_t,\theta})^2\,.
\end{align*}
On the event when $\theta_*\in C_{t+1}$, $C_{t+1}\not=\emptyset$ and hence $\hat\theta_t\in C_{t+1}$. Thus, we can write
\begin{align*}
C_{t+1} =
\{ \theta\in \R^d \,:\,
\norm{\theta-\hat\theta_t}_{V_t}^2 + \norm{\hat\theta_t}_2^2
+ \sum_{s=1}^t (\hat X_s – \ip{A_s,\hat \theta_t})^2 \le \beta_t(\delta) \}\,.
\end{align*}
Thus,
\begin{align*}
C_{t+1} \subset
\{ \theta\in \R^d \,:\, \norm{\theta-\hat\theta_t}_{V_t}^2 \le \beta_t(\delta) \}\,.
\end{align*}
Hence, our general theorem applies and gives that the UCB algorithm which uses $C_{t+1}$ as its confidence bound enjoys the following regret bound:
Theorem (UCB for sparse linear bandits): Fix some $\Theta\subset \R^d$ and assume that the strategy $\pi$ enjoys the regret bounds $(B_t)_t$ against $\Theta$. Then, with probability $1-\delta$, the pseudo-regret $\hat R_n = \sum_{t=1}^n \max_{a\in \cD_t} \ip{a,\theta_*} – \ip{A_t,\theta_*}$ of OLR-UCB satisfies
\begin{align*}
\hat R_n
\le \sqrt{ 8 d n \beta_{n-1}(\delta) \, \log\left( 1+ \tfrac{n L^2}{ d }\right) }\,,
\end{align*}
where $(\beta_{t})_t$ is given by \eqref{eq:betadef}.
Note that $\beta_n = \tilde{O}(B_n)$ and hence $\hat R_n = \tilde{O}( d B_n n )$.
To finish, let us quote a result for online sparse linear regression:
Theorem (Online sparse linear regression): There exists a strategy $\pi$ for the learner such that for any $\theta\in \R^d$, the regret $\rho_n(\theta)$ of $\pi$ against any strategic environment such that $\max_{t\in [n]}\norm{A_t}_2\le L$ and $\max_{t\in [n]}|X_t|\le X$ satisfies
\begin{align*}
\rho_n(\theta) \le c X^2 \norm{\theta}_0
\left\{\log(e+n^{1/2}L) + C_n \log(1+\tfrac{\norm{\theta}_1}{\norm{\theta}_0})\right\}
+ (1+X^2)C_n\,,
\end{align*}
where $c>0$ is some universal constant and $C_n = 2+ \log_2 \log(e+n^{1/2}L)$.
The strategy is a variant of the exponential weights method except that the method is now adjusted so that the set of experts is now $\R^d$. An appropriate sparsity prior is used and when predicting an appropriate truncation strategy is used. The details of the procedure are less important at this stage for our purposes and are thus left out. A reference to the work containing the missing details will be given at the end of the post.
Note that $A_n = O(\log \log(n))$. Hence, dropping the dependence on $X$ and $L$, for $p>0$, $\sup_{\theta: \norm{\theta}_0\le p, \norm{\theta}_2\le L} \rho_n(\theta) = O(p \log(n))$. Note how strong this is: The guarantee hold no matter what strategy the environment uses!
Now, in sparse linear bandits with subgaussian noise, the noise $(\eta_t)_t$ is not necessarily bounded, and as a consequence the rewards $(X_t)_t$ are also not necessarily bounded. However, the subgaussian property implies with probability $1-\delta$, $|\eta_t| \le \log(2/\delta)$. Now, choosing $\delta = 1/n^2$, we thus see that for problems with bounded mean reward, $\max_{t\in [n]} |X_t| \le X \doteq 1+\log(2n^2)$ with probability at least $1-1/n$. Putting things together then yields the announced result:
The expected regret of OLR-UCB when using the strategy $\pi$ from above satisfies
\begin{align*}
R_n = \tilde{O}( \sqrt{ d p n } )\,.
\end{align*}
Two important notes are in order: Firstly, while here we focused on the sparse case the results and techniques apply to other settings. For example, we can also get alternative confidence sets from results in online learning even for the standard non-sparse case. Or one may consider additional or different structural assumptions on $\theta$ (e.g., $\theta$, when reshaped into a matrix, could have a low spectral norm). Secondly, when the online linear regression results are applied it is important to use the tightest possible, data-dependent regret bounds $B_n$. In online learning most regret bounds start as tight, data-dependent bounds, which are then loosened to get further insight into the structure of problems. For our application, naturally one should use the tightest available regret bounds (or one should attempt to modify the existing proofs to get tighter data-dependent bounds). The gains from using data-dependent bounds can be very significant.
Finally, we need to emphasize that the sparsity parameter $p$ must be known in advance and that no algorithm can simultaneously enjoy a regret of $\Omega(\sqrt{d p n})$ for all $p$ simultaneously. This will be seen shortly in a post focusing exclusively on lower bounds for stochastic linear bandits.
Summary
In this post we considered sparse linear bandits in the stochastic setting. When the action was the hypercube we have shown a simple variant of the explore-then-commit strategy which selectively stops exploration in each dimension, independently of the others. We have shown that this strategy is able to adapt to the unknown sparsity of the parameter vector defining the linear bandit environment.
In the second part of the post we considered the more general setting when the action sets can change in time and they may lack the nice separable structure of the hypercube which made the first result possible. In this case we first argued that the dependence on the full dimensionality of the parameter vector is unavoidable. Then we constructed a method, OLR-UCB, which is a variant of UCB and which uses as a subroutine an online linear regression procedure. We showed that in the case of sparse linear bandits this gives a regret bound of $\tilde{O}(\sqrt{d p n })$. In our next post we will consider lower bounds for linear bandits and we will actually show that this bound is unimprovable in general.
References
The SETC algorithm is from a paper of the authors:
- Tor Lattimore, Koby Crammer, Csaba Szepesvári:
Linear Multi-Resource Allocation with Semi-Bandit Feedback. NIPS 2015: 964-972
Look at Appendix E if you want to see how things are done in this paper.
The construction for the sparse case is from another paper co-authored by one of the authors:
- Yasin Abbasi-Yadkori, Dávid Pál, Csaba Szepesvári:
Online-to-Confidence-Set Conversions and Application to Sparse Stochastic Bandits. AISTATS 2012: 1-9.
This paper has the few details that we have skipped in this blog.
Independently and simultaneously to this paper, Alexandra Carpentier and Remi Munos have also published a paper on sparse linear stochastic bandits:
- Alexandra Carpentier, Rémi Munos:
Bandit Theory meets Compressed Sensing for high dimensional Stochastic Linear Bandit. AISTATS 2012: 190-198
Their setting is a considerably different than the one studied here. In particular, they rely on the action set being nicely rounded and containing zero, while, perhaps, most importantly, the noise in their model effects the parameter vector: $X_t = \ip{A_t, \theta_*+\eta_t}$. Just like in the case of the hypercube this makes it possible to avoid the poor dependence on the dimension $d$: Their regret bounds take the form $R_n = O( p\sqrt{\log(d)n})$. We hope to return to discuss the differences and similarities between these two noise models in some later post.
The theorem on online sparse linear regression that we cited is due to Sebastien Gerschinovitz. The reference is
- Sébastien Gerchinovitz: Sparsity regret bounds for individual sequences in online linear regression. Journal of Machine Learning Research 14(1): 729-769 (2013)
The theorem cited here is Theorem 10 in the above paper.
A very recent paper by Alexander Rakhlin, Karthik Sridharan also discusses relationship between online learning regret bounds and self-normalized tail bounds of the type given here:
- Alexander Rakhlin, Karthik Sridharan: On Equivalence of Martingale Tail Bounds and Deterministic Regret Inequalities
Interestingly, what they show is that the relationship goes in both directions: Tail inequalities imply regret bounds and regret bounds imply tail inequalities.
I am told by Francesco Orabona that techniques similar to used here for constructing confidence bounds have been used earlier in a series of papers by Claudio Gentile and friends. For completeness, here is the list for further exploration:
- Ofer Dekel, Claudio Gentile, Karthik Sridharan:
Robust Selective Sampling from Single and Multiple Teachers. COLT 2010: 346-358 - Ofer Dekel, Claudio Gentile, Karthik Sridharan:
Selective sampling and active learning from single and multiple teachers. Journal of Machine Learning Research 13: 2655-2697 (2012) - Koby Crammer, Claudio Gentile:
Multiclass Classification with Bandit Feedback using Adaptive Regularization. ICML 2011: 273-280 - Koby Crammer, Claudio Gentile:
Multiclass classification with bandit feedback using adaptive regularization. Machine Learning 90(3): 347-383 (2013) - Claudio Gentile, Francesco Orabona:
On Multilabel Classification and Ranking with Partial Feedback. NIPS 2012: 1160-1168 - Claudio Gentile, Francesco Orabona:
On multilabel classification and ranking with bandit feedback. Journal of Machine Learning Research 15(1): 2451-2487 (2014)

A selfish advertisement (hope it’s helpful for readers too): The online-to-confidence-set conversion can be used for any generalized linear reward models (e.g., Bernoulli rewards whose mean is ). This can be done by feeding the negative log likelihood function as the loss function of the online learning algorithm. With this, the “generalized” linear bandit problem can be solved as fast as the standard linear bandit. Details can be found in Jun et al., Scalable Generalized Linear Bandits: Online Computation and Hashing, NIPS 2017.